How to Set Up Nightly Backups to AWS S3 for Multiple Neon Projects
Schedule a Github Action to move data from your Neon projects to S3 every night - Part 2

This is the second post of a series on automating nightly backups for multiple Neon projects. In the first post, I covered how to configure AWS to set up the S3 buckets. In this post, I’ll explain how to set up nightly backups for multiple Neon Postgres databases using GitHub Actions and pg_dump/restore.
There are three main components to creating this kind of scheduled backup:
- AWS
- You’ll need to know your AWS Account ID and have permissions that allow you to create Roles, Identity Providers, S3 buckets, and be able to update bucket policies.
- Postgres Database
- You’ll need to know the connection strings for your databases, which region the databases are deployed, and which version of Postgres your databases use.
- GitHub Action
You’ll also need to have permission to access Actions and Settings > Secrets in the GitHub repository you’d like to run the Actions from.
The approach I’ll be using involves configuring a single S3 bucket to hold multiple folders, each with backup files created by a GitHub Action. The simplest approach I’ve found for running multiple backups with GitHub Actions is to create separate Actions, each responsible for their own schedule and managing a single database instance. The code I’ll be discussing in this post covers a single Action, but the same method can be applied to multiple Actions.
You can see all the code i’ll be referencing on the GitHub link below:
Neon project setup
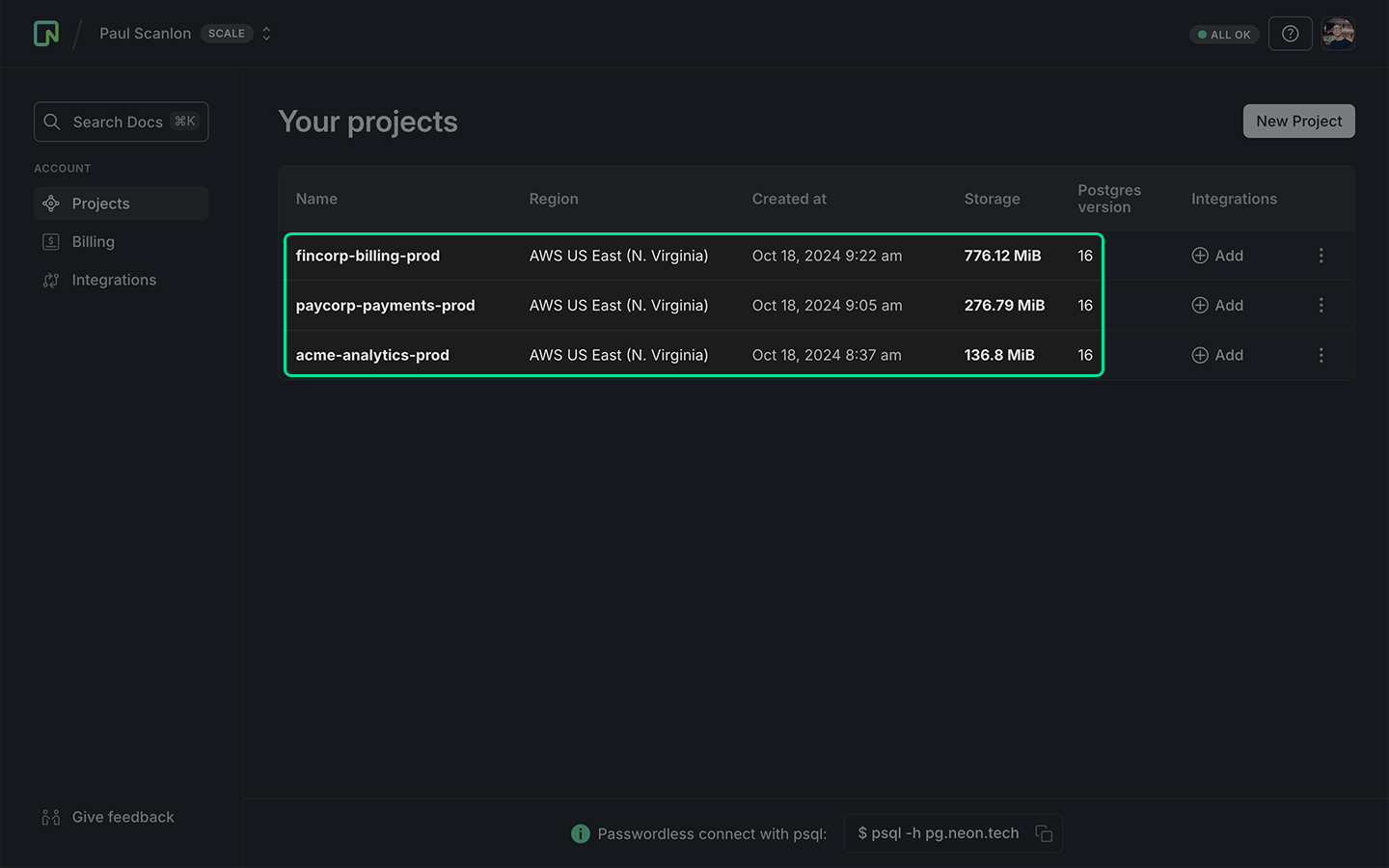
Before diving into the code, here’s a look at my Neon console dashboard. I have three databases set up for three fictional customers, all running Postgres 16 and all are deployed to us-east-1.
My goal is to back up each database into its own folder within an S3 bucket, with different schedules and retention periods.
Scheduled pg_dump/restore GitHub Action
Using the same naming conventions i’ve created three new files in the .github/workflows folder, these are:
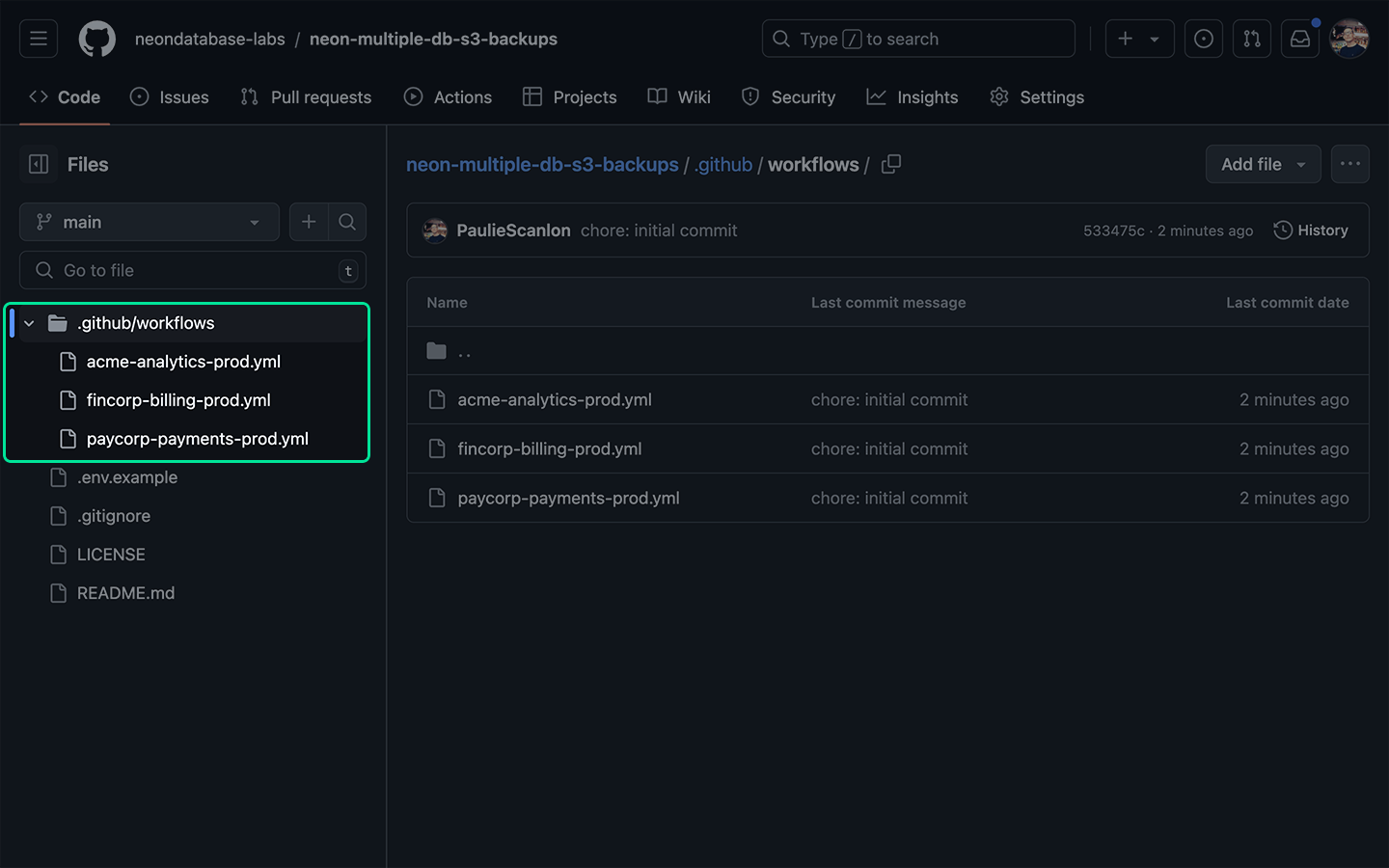
All the Actions are technically the same, (besides the name of the file), but there are several areas where they differ.
These are:
- The workflow
name - The
DATABASE_URL - The
RETENTIONperiod
For example, in the first .yml file, the workflow name is acme-analytics-prod, the DATABASE_URL points to secrets.ACME_ANALYTICS_PROD, and the RETENTION period is 7 days.
Here’s the full Action, and below the code snippet, i’ll explain how it all works.
// .github/workflows/acme-analytics-prod.yml
name: acme-analytics-prod
on:
schedule:
- cron: '0 0 * * *' # Runs at midnight
workflow_dispatch:
jobs:
db-backup:
runs-on: ubuntu-latest
permissions:
id-token: write
env:
RETENTION: 7
DATABASE_URL: ${{ secrets.ACME_ANALYTICS_PROD }}
IAM_ROLE: ${{ secrets.IAM_ROLE }}
AWS_ACCOUNT_ID: ${{ secrets.AWS_ACCOUNT_ID }}
S3_BUCKET_NAME: ${{ secrets.S3_BUCKET_NAME }}
AWS_REGION: 'us-east-1'
PG_VERSION: '17'
steps:
- name: Install PostgreSQL
run: |
sudo apt install -y postgresql-common
yes '' | sudo /usr/share/postgresql-common/pgdg/apt.postgresql.org.sh
sudo apt install -y postgresql-${{ env.PG_VERSION }}
- name: Set PostgreSQL binary path
run: echo "POSTGRES=/usr/lib/postgresql/${{ env.PG_VERSION }}/bin" >> $GITHUB_ENV
- name: Configure AWS credentials
uses: aws-actions/configure-aws-credentials@v4
with:
role-to-assume: arn:aws:iam::${{ env.AWS_ACCOUNT_ID }}:role/${{ env.IAM_ROLE }}
aws-region: ${{ env.AWS_REGION }}
- name: Set file, folder and path variables
run: |
GZIP_NAME="$(date +'%B-%d-%Y@%H:%M:%S').gz"
FOLDER_NAME="${{ github.workflow }}"
UPLOAD_PATH="s3://${{ env.S3_BUCKET_NAME }}/${FOLDER_NAME}/${GZIP_NAME}"
echo "GZIP_NAME=${GZIP_NAME}" >> $GITHUB_ENV
echo "FOLDER_NAME=${FOLDER_NAME}" >> $GITHUB_ENV
echo "UPLOAD_PATH=${UPLOAD_PATH}" >> $GITHUB_ENV
- name: Create folder if it doesn't exist
run: |
if ! aws s3api head-object --bucket ${{ env.S3_BUCKET_NAME }} --key "${{ env.FOLDER_NAME }}/" 2>/dev/null; then
aws s3api put-object --bucket ${{ env.S3_BUCKET_NAME }} --key "${{ env.FOLDER_NAME }}/"
fi
- name: Run pg_dump
run: |
$POSTGRES/pg_dump ${{ env.DATABASE_URL }} | gzip > "${{ env.GZIP_NAME }}"
- name: Empty bucket of old files
run: |
THRESHOLD_DATE=$(date -d "-${{ env.RETENTION }} days" +%Y-%m-%dT%H:%M:%SZ)
aws s3api list-objects --bucket ${{ env.S3_BUCKET_NAME }} --prefix "${{ env.FOLDER_NAME }}/" --query "Contents[?LastModified<'${THRESHOLD_DATE}'] | [?ends_with(Key, '.gz')].{Key: Key}" --output text | while read -r file; do
aws s3 rm "s3://${{ env.S3_BUCKET_NAME }}/${file}"
done
- name: Upload to bucket
run: |
aws s3 cp "${{ env.GZIP_NAME }}" "${{ env.UPLOAD_PATH }}" --region ${{ env.AWS_REGION }}Starting from the top there are a few configuration options:
Action configuration
The first part of the Action defines a name for the Action and when it should run.
name: acme-analytics-prod
on:
schedule:
- cron: '0 0 * * *' # Runs at midnight
workflow_dispatch:name: This is the workflow name and will also be used when creating the folder in the S3 bucketcron: This determines how often the Action will run, take a look a the GitHub docs where the POSIX cron syntax is explained
Environment variables
The next part deals with environment variables. Some variables are set “inline” in the Action but others are defined using GitHub Secrets.
env:
RETENTION: 7
DATABASE_URL: ${{ secrets.ACME_ANALYTICS_PROD }}
IAM_ROLE: ${{ secrets.IAM_ROLE }}
AWS_ACCOUNT_ID: ${{ secrets.AWS_ACCOUNT_ID }}
S3_BUCKET_NAME: ${{ secrets.S3_BUCKET_NAME }}
AWS_REGION: 'us-east-1'
PG_VERSION: '17'RETENTION: This determines how long a backup file should remain in the S3 bucket before it’s deletedDATABASE_URL: This is the Neon Postgres connection string for the database you’re backing upIAM_ROLE: This is the name of the AWS IAM RoleAWS_ACCOUNT_ID: This is your AWS Account IdS3_BUCKET_NAME: This the name of the S3 bucket where all backups are being storedAWS_REGION: This is the region where the S3 bucket is deployedPG_VERSION: This is the version of Postgres to install
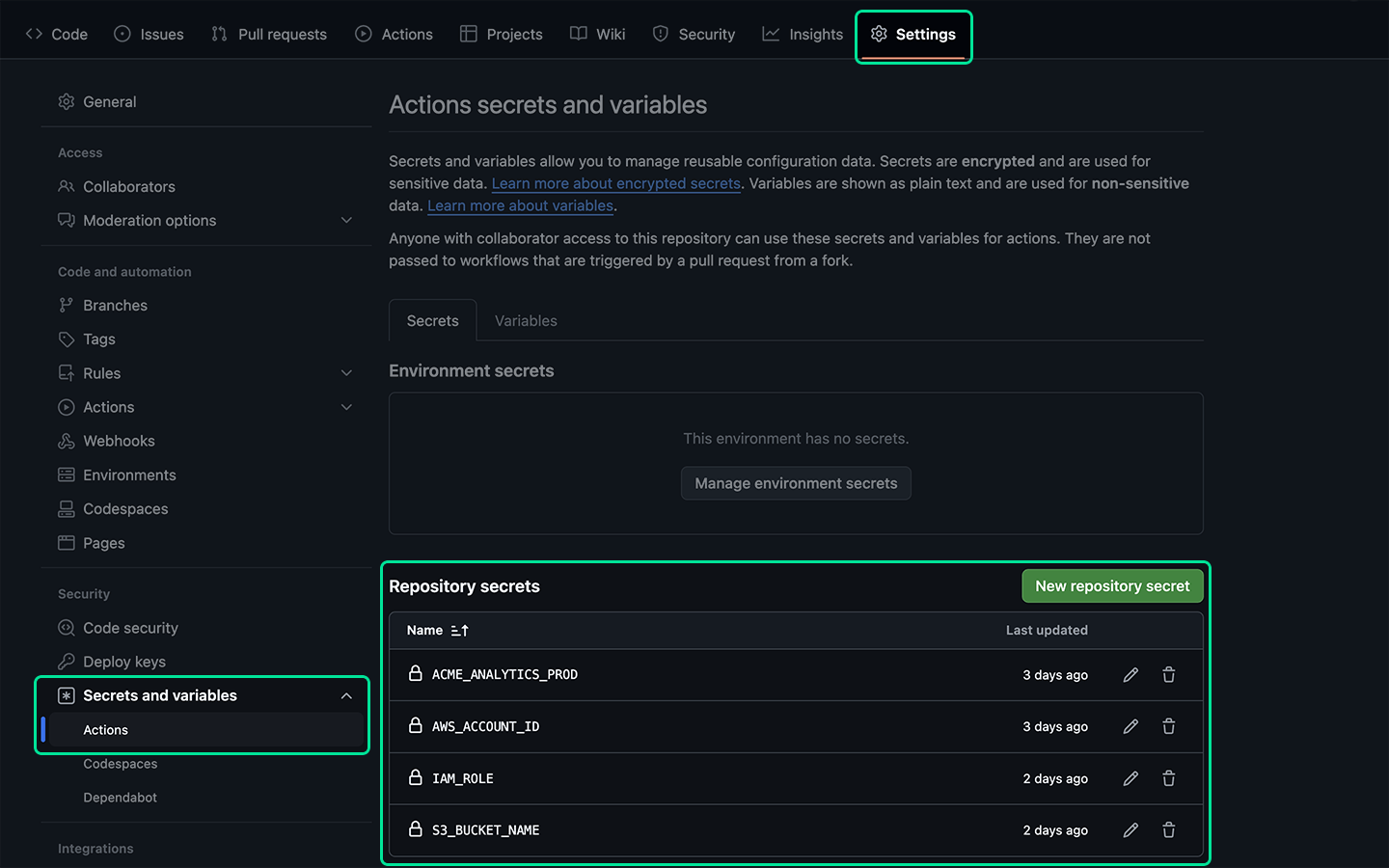
GitHub Secrets
As outlined above several of the above environment variables are defined using secrets. These variables can be added to Settings > Secrets and variables > Actions.
Here’s a screenshot of the GitHub repository secrets including the connection string for the fictional ACME Analytics Prod database.
Action steps
I’ll now explain what each step of the Action does.
Install PostgreSQL
This step installs Postgres into the GitHub Action’s virtual environment. The version to install is defined by the PG_VERSION environment variable. The Potgres binary can then be referenced by using $POSTGRES.
- name: Install PostgreSQL
run: |
sudo apt install -y postgresql-common
yes '' | sudo /usr/share/postgresql-common/pgdg/apt.postgresql.org.sh
sudo apt install -y postgresql-${{ env.PG_VERSION }}
- name: Set PostgreSQL binary path
run: echo "POSTGRES=/usr/lib/postgresql/${{ env.PG_VERSION }}/bin" >> $GITHUB_ENVConfigure AWS credentials
This step configures AWS credentials within the GitHub Action virtual environment, allowing the workflow to interact with AWS services securely.
- name: Configure AWS credentials
uses: aws-actions/configure-aws-credentials@v4
with:
role-to-assume: arn:aws:iam::${{ env.AWS_ACCOUNT_ID }}:role/${{ env.IAM_ROLE }}
aws-region: ${{ env.AWS_REGION }}Set file, folder and path variables
In this step I’ve created three variables that are all output to GITHUB_ENV. This allows me to access the values from other steps in the Action.
- name: Set file, folder and path variables
run: |
GZIP_NAME="$(date +'%B-%d-%Y@%H:%M:%S').gz"
FOLDER_NAME="${{ github.workflow }}"
UPLOAD_PATH="s3://${{ env.S3_BUCKET_NAME }}/${FOLDER_NAME}/${GZIP_NAME}"
echo "GZIP_NAME=${GZIP_NAME}" >> $GITHUB_ENV
echo "FOLDER_NAME=${FOLDER_NAME}" >> $GITHUB_ENV
echo "UPLOAD_PATH=${UPLOAD_PATH}" >> $GITHUB_ENVThe three variables are as follows:
GZIP_NAME: The name of the .gz file derived from the date which would produce a file name similar to,October-21-2024@07:53:02.gzFOLDER_NAME: The folder where the .gz files are to be uploadedUPLOAD_PATH: This is the full path that includes the S3 bucket name, folder name and .gz file
Create folder if it doesn’t exist
This step creates a new folder (if one doesn’t already exist) inside the S3 bucket using the FOLDER_NAME as defined in the previous step.
- name: Create folder if it doesn't exist
run: |
if ! aws s3api head-object --bucket ${{ env.S3_BUCKET_NAME }} --key "${{ env.FOLDER_NAME }}/" 2>/dev/null; then
aws s3api put-object --bucket ${{ env.S3_BUCKET_NAME }} --key "${{ env.FOLDER_NAME }}/"
fiRun pg_dump
This step runs a pg_dump on the database and saves the output in virtual memory using the GZIP_NAME as defined in the previous step.
- name: Run pg_dump
run: |
$POSTGRES/pg_dump ${{ env.DATABASE_URL }} | gzip > "${{ env.GZIP_NAME }}"Empty bucket of old files
This optional step checks the contents of FOLDER_NAME and identifies any .gz files that are older than the number of days specified by the RETENTION variable.
- name: Empty bucket of old files
run: |
THRESHOLD_DATE=$(date -d "-${{ env.RETENTION }} days" +%Y-%m-%dT%H:%M:%SZ)
aws s3api list-objects --bucket ${{ env.S3_BUCKET_NAME }} --prefix "${{ env.FOLDER_NAME }}/" --query "Contents[?LastModified<'${THRESHOLD_DATE}'] | [?ends_with(Key, '.gz')].{Key: Key}" --output text | while read -r file; do
aws s3 rm "s3://${{ env.S3_BUCKET_NAME }}/${file}"
doneUpload to bucket
And lastly, this step uploads the .gz file created by the pg_dump step and uploads it to the correct folder within the S3 bucket.
- name: Upload to bucket
run: |
aws s3 cp "${{ env.GZIP_NAME }}" "${{ env.UPLOAD_PATH }}" --region ${{ env.AWS_REGION }}And that’s it!
Finished
You could create as many of these Actions as you need. Just be careful to double check the DATABASE_URL to avoid backing up a database to the wrong folder.
Oh, and just a note on limitations. GitHub Actions will timeout after ~6 hours. Depending on how large your database is and how you’ve configured it will determine how long the pg_dump step takes. If you do experience timeout issues, you can self host GitHub Action runners, as explained in the docs. About self-hosted runners.
Neon is a Postgres provider that takes the world’s most loved database and delivers it as a serverless platform with autoscaling, scale-to-zero, and database branching. Get started with our Free Plan in seconds (no credit card required).