Vibe Coding With AI to Generate Synthetic Data: Part 1
Exploring vibe coding with Anthropic: Can AI handle seed data generation?

In this blog post, I’ll share my experience of vibe coding as I explore AI-driven synthetic data generation, the tests I ran, and the challenges I faced along the way.
What is vibe coding?
Vibe coding is all about skipping the boilerplate and getting straight to the good stuff. Instead of meticulously crafting every line of code, you describe what you want in natural language and let AI handle the details, and it sounds like the right approach for generating synthetic data, right?
Using AI for synthetic data generation
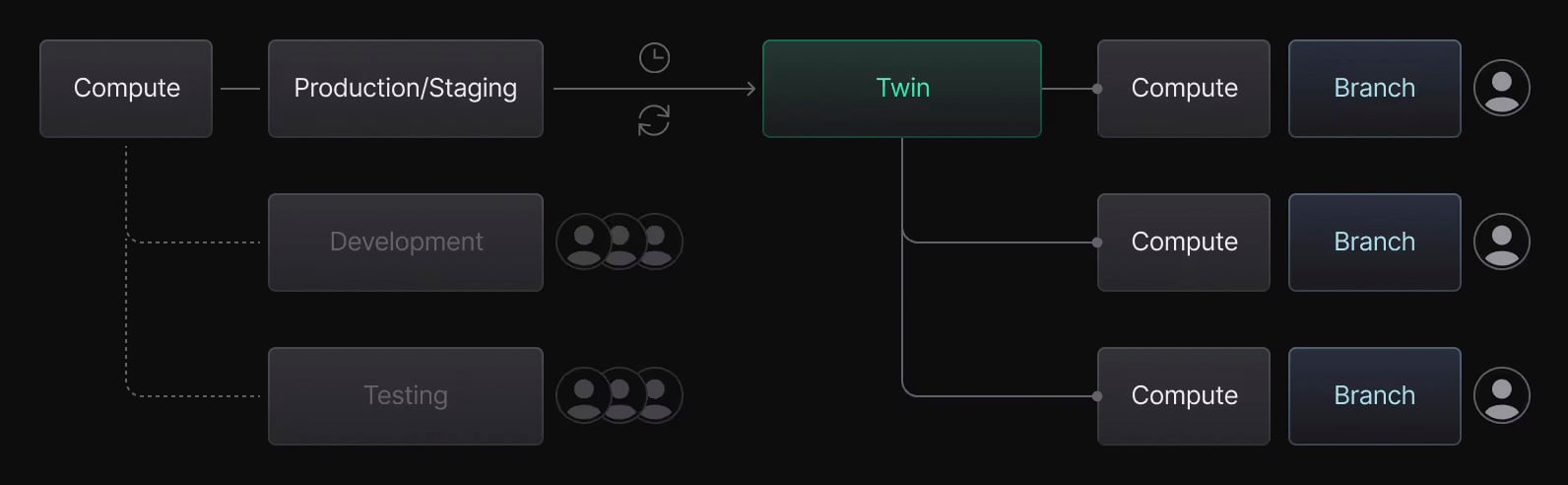
But, before I go any further, let me take a step back and explain why I started exploring AI for synthetic data generation. At Neon, I’ve been focused on improving our Dev/Test workflows. Simply put, this means keeping production where it is while shifting development and testing environments to Neon. You can read more about this workflow here: From Shared Chaos to Isolated Control with Neon.
AI requirements for generating synthetic data
To integrate synthetic data generation into our Twin workflows, the process needs to be seamless, scalable, and hands-off. Rather than relying on manual setup or maintenance, I want an approach that adapts dynamically and works universally across different Postgres databases, large and small, but that’s not all:
- The process should be fully automated.
- It should run just like the Full and Partial Twin workflows.
- No manual management of seed data generation scripts.
- It must work with any PostgreSQL schema.
- New synthetic data should be generated automatically with every production schema change.
Synthetic data generation using Anthropic
It might sound complex, but the process is fairly straightforward. The plan is to set up a GitHub Action that connects to a production/staging database, performs a schema-only dump, and stores the schema file as an Action artifact for use in later workflow steps. This schema is then included in a prompt sent to the Anthropic API, instructing the model to generate realistic data that aligns with the schema provided.
GitHub repository
The link below contains all the code from my experiments. In the two cases outlined in this post, my approach integrates GitHub Actions as the job runner to manage database connections alongside a JavaScript file for making the API request to Anthropic.
- Repository link: vibe-coding-synthetic-data-part-1
The general structure of the repo looks like this:
.github
|-- scripts
|-- name-of-script.mjs
|-- workflows
|-- name-of--workflow.ymlUsing AI only to generate data
In my first attempt, I relied entirely on AI to generate the data. I instructed the model to read the schema, maintain foreign key relationships, and generate the correct data types for each table and column. Finally, I asked it to return only fully qualified SQL INSERT statements, which I planned to use with psql in a later step.
You can see the files used in this experiment on the following links:
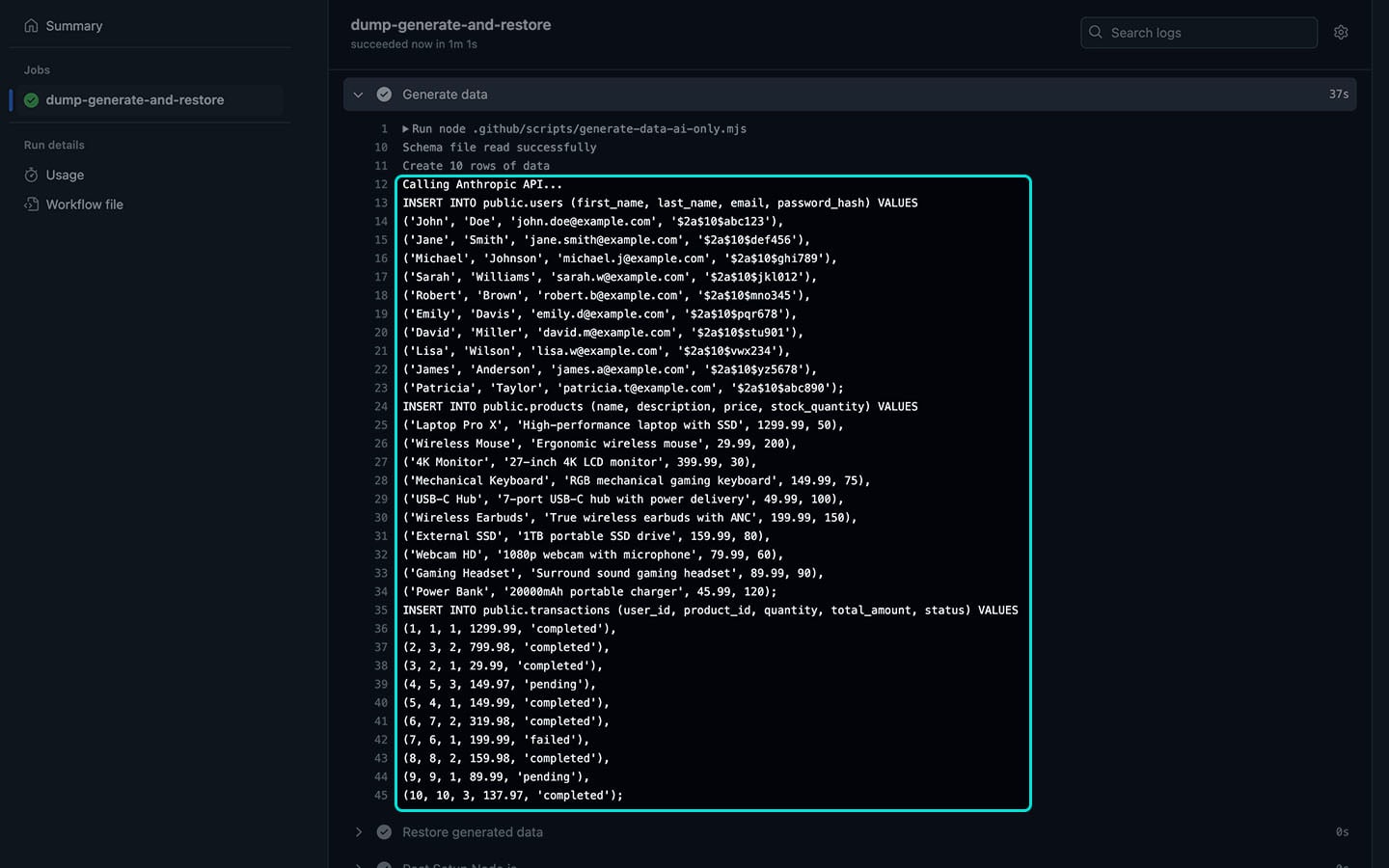
AI only claude-3-5-sonnet-20241022
This model successfully generated SQL INSERT statements for synthetic data, but it started to fail after approximately 75 rows. The primary issue was loss of referential integrity; for example, some columns attempted to reference user_ids or product_ids that didn’t exist, causing errors in the insertion process.
| Amount of rows | Status | Explanation |
| 10 | ✅ Pass | N/A |
| 20 | ✅ Pass | N/A |
| 100 | ❌ Fail | Relation does not exist |
AI only claude-3-7-sonnet-20250219
This model frequently returned the error message “Model overloaded. Please try again later.” While some requests were successful, it often failed to generate valid SQL INSERT statements.
| Amount of rows | Status | Explanation |
| (n) | ❌ Fail | Model overloaded. Please try again later. | Failed to generate valid SQL INSERT statements |
With this AI-only approach, the model struggles to manage all the necessary details. Even with a small schema, generating just 100 rows across three tables proves too complex. Using this approach both models eventually fail to maintain foreign key relationships, resulting in PostgreSQL errors when executing the INSERT statements.
Using AI with faker.js to generate data
In this attempt, I’ve opted for a hybrid approach. As before, I instructed the model to read the schema, but instead of asking the model to generate SQL INSERT statements, I asked it to create structured JavaScript objects that matched the schema and used faker.js to generate the data. Finally, I iterate over each object and convert the data into fully qualified SQL INSERT statements, which I planned to use with psql in a later step.
You can see the files used in this experiment on the following links:
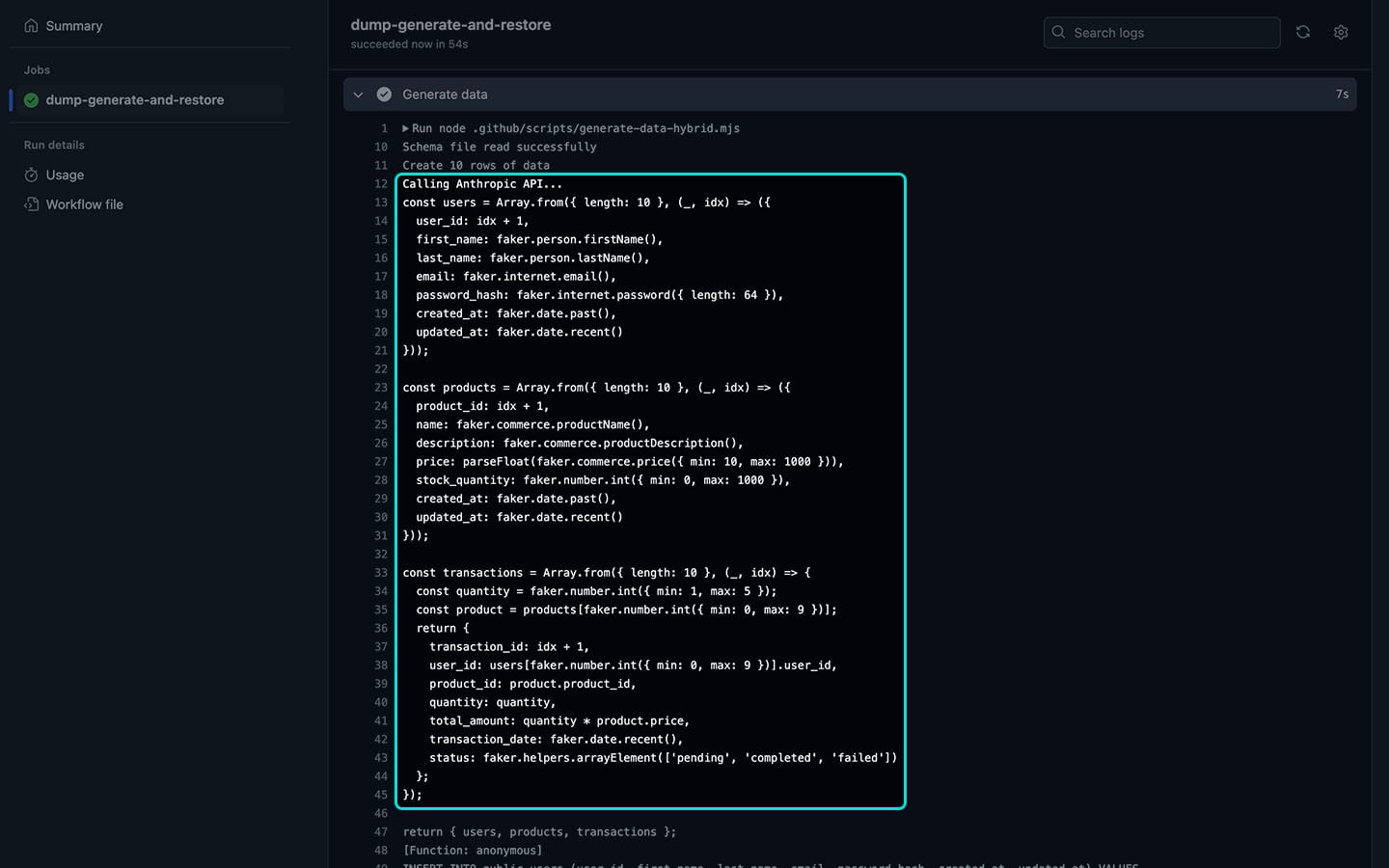
Hybrid claude-3-5-sonnet-20241022
This model successfully generated the correc JavaScript and faker.js code, which could be used to generate fully qualified SQL INSERT statements, but it started to fail after ~3500 rows. The primary issue was loss of referential integrity; as before, some columns attempted to reference user_ids or product_ids that didn’t exist, causing errors in the insertion process.
| Amount of rows | Status | Explanation |
| 10 | ✅ Pass | N/A |
| 50 | ✅ Pass | N/A |
| 100 | ✅ Pass | N/A |
| 200 | ✅ Pass | N/A |
| 400 | ✅ Pass | N/A |
| 1000 | ✅ Pass | N/A |
| 3000 | ✅ Pass | N/A |
| 5000 | ❌ Fail | Relation does not exist |
Hybrid claude-3-7-sonnet-20250219 + faker.js
This model frequently returned the error message “Model overloaded. Please try again later.” While some requests were successful, it often failed to generate valid SQL INSERT statements.
| Amount of rows | Status | Explanation |
| (n) | ❌ Fail | Model overloaded. Please try again later. | Failed to generate valid SQL INSERT statements |
General-Purpose Models Continued
I ran a similar set of tests using OpenAI’s GPT-4.5 model, and the results aligned with my previous attempts. The model successfully generated fully qualified SQL INSERT statements and well-structured JavaScript / faker.js code. However, as the number of rows increased, it struggled to maintain referential integrity. I suspect that with a more complex schema, the model would encounter issues when generating a relatively small dataset.
Conclusion
This was my first real attempt at prompt engineering, and there’s a good chance that general-purpose models can handle this task—if given the right instructions. As you might have noticed from my prompts, I didn’t exactly set them up for success. Part of that was intentional—I wanted to see how well the model could understand the schema on its own. But there’s also the question of effort: providing detailed examples, defining relationships, and guiding the model more explicitly might, in the end, become just as much work as manually managing seed scripts.
That said, my next step is to refine my prompt-writing skills and experiment with ways to help the model reason more effectively. I’ve seen some interesting courses on deeplearning.ai that could help with that, so I’ll probably start there and see if I can improve the results.
But only time will tell. Stay tuned—I’ll be back soon with another post!